How to buy bitcoin in Thailand


Following Singapore, the Philippines and other countries in Southeast Asia, Thailand is actively developing in the field of digital payments. Despite the fact that cryptocurrencies are not regulated at the legislative level, Bitcoin is not prohibited in Thailand, and the country's authorities predict the imminent official recognition of cryptocurrencies and the release of a national digital currency.
Bitcoin is considered the most famous and sought-after cryptocurrency in the world market, and therefore more and more different online platforms are opening on the network. With unlimited choice, it is difficult for new users to decide on a service that allows them to buy Bitcoin at the current market price. Increasingly, Thai users are paying attention to Itez, an official service from the Estonian regulator that interacts with banks around the world, including Thailand. You can buy bitcoin on our service with Thai baht, dollars and other currencies. Just follow the step by step instructions.
In order to buy bitcoin, it is not necessary to register on the Itez website. In a handy calculator, you can quickly calculate the cost of BTC based on the amount you plan to use for payment. The smallest purchase amount in dollar terms is 30 USD. By the way, the same applies to the euro - the starting purchase threshold starts at €30. Well, in our instructions, as promised, we will go through all the stages of purchase BTC for dollars step by step.
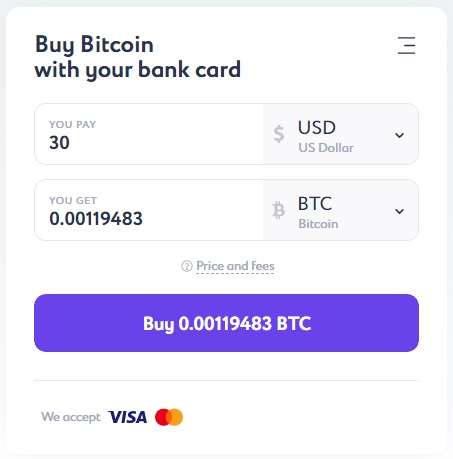
After converting the currency to BTC, you will see the final result in the "You Get" field and on the "Buy" button. Click the button and enter your email address in the following window.
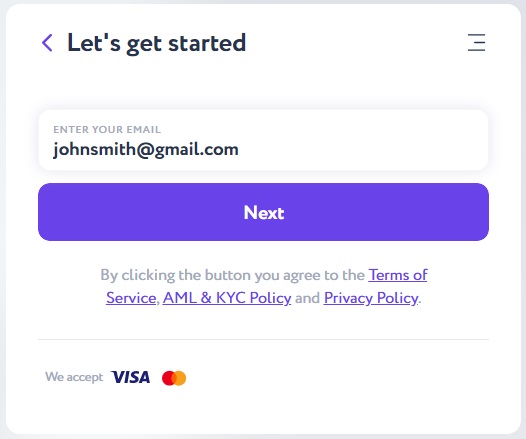
Verify your email with a 6-digit code sent to the previously indicated e-mail and click the "Verify" button.
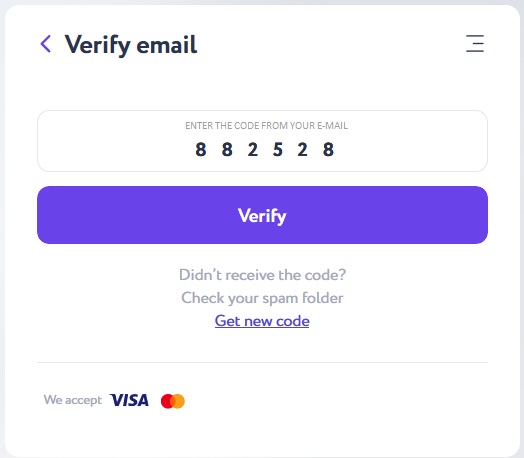
Specify the purchase amount in the Itez dialog box. Copy the recipient address - your bitcoin wallet - from the “Accept” section.
Important: you should not manually copy the bitcoin wallet address. The blockchain system does not give any information about bitcoin addresses problems, and if an error occurs during manual entry, all the buyer's funds may be lost.
For example, this is how the copy address button looks like in the Exodus wallet:
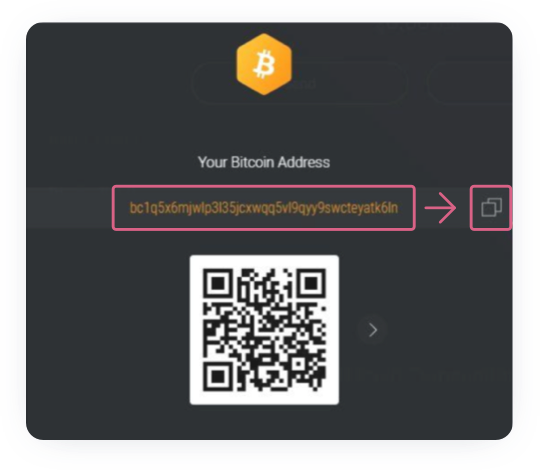
After copying the bitcoin wallet address, paste it into the dialog box.
Check your data — it is important to make sure that the address is entered correctly.
Don't have a crypto wallet?
Create your convenient and secure itez Wallet in just a few minutes!
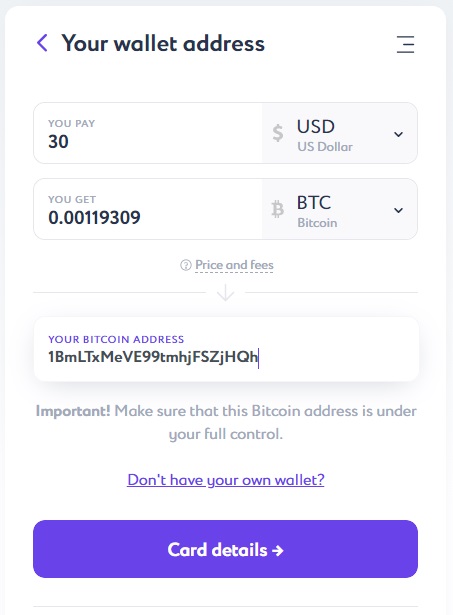
After pushing the “Card details” button, enter the required card information: card number and expiration date, the cardholder name and CVC-code — three numbers on the back of the card.
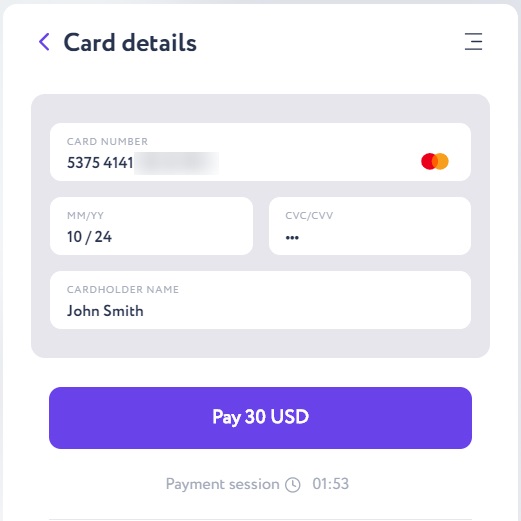
Push the “Pay” button and enter the one-time bank code in the following window. As soon as the transaction receives 6 confirmations in the blockchain network, your bitcoin wallet balance will be top-up.
Important: the transaction will wait for confirmations for time. After six network confirmations, bitcoin will be on your e-wallet; when buying with Itez it will take for about 15 minutes. This is a very good speed for the Bitcoin network since transactions in the most popular blockchain network are somewhat slower than in other networks due to its properties and high load.
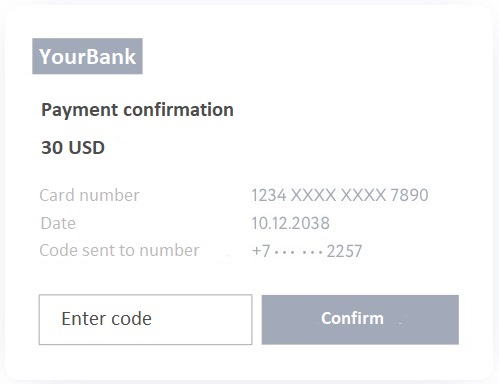
The transaction will first wait for confirmations from the blockchain network.
After six confirmations, the BTC networks will be yours for good; when buying from Itez, this will happen on average within 15 minutes.
This is a very good indicator for the Bitcoin network, since transactions are somewhat slower in the most popular blockchain network than in other networks, due to its design features and high workload.

The list of the most popular banks in Thailand is headed by Bangkok Bank, Krungthai Bank, Siam Commercial Bank, Kasikorn Bank and TMB Bank.

The service Itez works with cards of major payment systems Visa, MasterCard, American Express and others. The choice is due to the fact that international payment systems are more loyal to cryptocurrency transactions, without interfering with the exchange and without blocking transfers.

Thailand is one of the countries that actively use the e-wallet system for storing electronic money, and therefore, Thai users are careful in choosing a tool for storing Bitcoin and other cryptocurrencies. You can get acquainted with the existing wallets and choose the most suitable one by following the link https://bitcoin.org/ru/choose-your-wallet
Itez is an instant bitcoin purchase resource. Itez is a certified operator holding a license to sell and store cryptocurrencies of a financial regulator from Estonia. What does this give to customers?
First of all it is safety, since the operator is fully responsible for the risks. He conducts a compliance check, provides cryptocurrency on time and is always in touch with customers, if the need arises. Secondly, it`s efficient. The average time for receiving bitcoin to a client's account is a quarter of an hour. For comparison, let's take similar services Indacoin and MoonPay: when working with them, the time it takes for bitcoin to be credited to the client's electronic wallet will take for about an hour - it depends on how busy the network is. Thirdly, the service offers to customers a favorable exchange rate. Rate changes occur in accordance with the liquidity provider's information, therefore, the BTC value on the Itez website is as close as possible to the market value. The site has no hidden fees as the final BTC value is displayed instantly. If the purchase price does not exceed € 300, then the buyer does not need verification.










 How to buy bitcoin in Philippines
How to buy bitcoin in Philippines How to buy bitcoin in the United Kindom
How to buy bitcoin in the United Kindom How to buy bitcoin in Brazil
How to buy bitcoin in Brazil How to buy Tether in Thailand
How to buy Tether in Thailand How to buy Ethereum in Thailand
How to buy Ethereum in Thailand